
Yuqi Qian
Rail Developer - Quick Learner
Rail Developer - Quick Learner


After graduating from Peking University, Yuqi started her study in computer science as a master student in GaTech, where she get in touch in web development. Trying out ASP.net and Django, she finally chosed Ruby on Rails as the key to web development.
Several months of coding training gave her a sharp sense of developing and debugging, which made her more creative, prudent, and eager to embrace new knowlege.
Copacescc is a web application and a windows universal application which built for Georgia Department of Transportation to collect, manage, and analyse data of roads and path.
Copacescc provides a user-friendly interface to adding, editing, and deleting roads and segments, to review previous data by customized time-cycle and to generate report for selected data.
The website is right now running at: Copaces-CC
Yelp does not provide keywords from its reviews. In a typical webpage of a store in Yelp, wordy reviews form a large part of the page. It might meet the expectation of the keen sharer that their opinion is presented at a eye-catching plot, however, those who only want to get the general impression of the store in a limited time will find this layout too time-consuming. And compared to Yelp.com, Amazon.com provides much better user experience. Therefore, in our project, we create a review refiner to find the keywords from yelp reviews. It offers the visitors with succinct description about this store, and saves time for those who has limited time to visit the website. We use different algorithms to generate keywords (TF-IDF and NLP), then the generated keywords can be presented on our website.
Yelp is a very useful tool for users to find shops they need. Users need to get the information from yelp reviews down below the shop website. However, yelp shops usually contain hundreds of reviews and sometimes the review could be very long. As a result, it takes a lot of time for users to get a brief impression on a yelp shop since so many long reviews need to be read. Therefore, we think the efficiency of yelp can be highly improved. In our project, we try to create a review refiner to generate keywords from yelp reviews to improve the efficiency of yelp.
Our project use Django to build the web framework, and choose python as programming language. For text mining, the TF-IDF algorithm and application of NLP are used to satisfy our main goal for extraction the keywords. Here’s our brief introduction of our method.
We choose TF-IDF algorithm to calculate and weight all candidates’ keywords we generated. The most popular method now is just using the TF (Term Frequency) to weight the keywords. Although this is a fast way to generate keywords, it may reduce the accuracy to some extent since when comparing with a set of documents, the words, which are popular in most of this data set, will also be chosen as keywords of certain documents. However, our usage of TF-IDF solves such problem since the algorithm checks all the dataset and returns the answers.
1) Set up building environment
For the implement of the algorithms, first we need to setup some libraries on python. For python version 2.7.9, we setup scipy(version 0.15.1), numpy(version 1.9.2) and NLTK(version 3.0) for further coding.
2) Extract comments information from .txt file
In the test, we generate a .txt file of a set of comments information which containing elements such as user id, review id, date and stars. The first step is to extract comments text from this file. This method uses re library for implement.
3) TF-IDF algorithm
TF-IDF is shorten for Term Frequency–Inverse Document Frequency, a wideused method for text analysis. It is implemented by TF and IDF separately. While in use of extraction keywords, basically we can easily assume that the more times the word appear, the more importance the word is for a certain document. The appearance times of words, of course excluding all the stop words, is defined as Term Frequency for documents. It, however, may cause another problem that there’re some wide-used words always appear many times in different documents such as “I”, “we” and etc. In other words, the words, which are not common in other documents, with a high appearance times in certain document can represent the main idea of the text. That’s called Inverse Document Frequency. Thus the combination of TF and IDF generate sorted words from the most importance to the least.
For application, the code is written as below. float (v) indicates the
appearance times of candidate keywords in certain text(topic), sum_tf
represents the total words in text(topic), float(sum_topics) indicates the
total texts(topics) for analysis and df[k] represents number of the texts
containing the certain candidate keywords.
df = {}
topics = cfd.conditions()
sum_topics = len(topics)
for topic in topics:
for k in cfd[topic].keys():
if k not in df:
df[k] = 0
df[k] += 1
topic_tf_idf = {}
for topic in topics:
if topic not in topic_tf_idf:
topic_tf_idf[topic] = {}
sum_tf = len(corpus[topic])
for k, v in cfd[topic].items():
topic_tf_idf[topic][k] = float(v) / sum_tf * log(float(sum_topics)/df[k])
4) Phrase generation by NLTK
The above TF-IDF algorithm is the main method for our project. However, it can just analyze words in documents separately without the combination of adjective and noun. In our test, this will arise confusion for users so this step is mainly about how to generate phrases instead of words as keywords. Here are several functions we write.
The generate_candidate_keywords function generates keywords as phrases and
words. The basic idea of this function is, for the sentences without signals
above, to replace all stop words with “/” and based on this signal generate
phrases and words as candidate.
def _generate_candidate_keywords(sentences):
phrase_list = []
for sentence in sentences:
words = map(lambda x: "|" if x in nltk.corpus.stopwords.words() else x, nltk.word_tokenize(sentence.lower()))
phrase = []
for word in words:
if word == "|" or isPunct(word):
if len(phrase) > 0:
temp = ' '.join(phrase)
phrase_list.append(temp)
phrase = []
else:
phrase.append(word)
return phrase_listWe first tried to access reviews via Yelp API, but it only provides one random review per store, which is far from enough to generate the keywords. Therefore, we can only get a static data set from Yelp Data set Challenge program.
The data set provided by the program is as large as 1.4 GB. We use Python and Regular Expression to clean the data and keep useful data, including name, id, location, and corresponding reviews for each store. Then we use SQLite software to convert data format to JSON for further treatment. The final data set is 1.09 GB and has 1.6 million records of reviews. The JSON format is {“id”: “xxx”, “review”: “xxx”} for each.
Approach
We use NLP Algorithm to generate a group of keywords, by splitting sentences into words and phases with help of Nature language Toolkit (NLTK). Then we apply TF-IDF Algorithm on these words and phases to pick out the most unique ones according to the relevance to text.
This is an improved method comparing with just the frequency of words in a certain documents since it can split some unique words always appearing in most documents. However, there is an obvious disadvantage of this method, the running time of this greedy algorithm will increase rapidly.
We have got access to a static data set of Yelp’s reviews rather than by dynamic request via Yelp’s API. It is not flexible, but it is low cost and can run fast. The data is very big, which contains 1.6 million records of reviews after data cleaning, which is enough to generate keywords with high credibility.
Our project is mainly about text mining. Therefore, text-mining algorithms have been implemented on our data and they can generate the keywords and phrases from reviews. The main algorithms are NLP algorithm (based on nature language toolkit) and TF-IDF algorithm (based on the keywords generated by NLP algorithm). NLP algorithm works well since it is powerful enough to generate keywords as well as phrases. Additionally, we applied TF-IDF algorithm, which is an accurate algorithm. However, there exists an obvious drawback according to it’s time cost. Therefore, we applied several simplifications on our algorithm to reduce the running time, for example, randomly choose a smaller data set while generating the keywords. The webpage is deployed locally, which is available in the package as a demo.
Also there are something we can do to improve our project, while because of the limited time, we just list them below.
1) To import the data into server database. It may speed up the algorithm and apply a steadier environment to design a webpage.
2) To do sentiment analysis based on the literature review. Based on our research, within many ways to do sentiment analysis on the keywords, the most suitable one for us is the usage of Python with package “TextBlob”. Actually, we plan to extract the number of certain keywords and show if it’s positive or not. It’s a text-mining tool built on the base of NLTK.
3) To eliminate some confusing keywords and phrases, algorithm can be improved by combining more functions provided by natural language toolkit.
After optimizing the algorithm part, we have plugged the python program into our webpage and finished the interface between web framework and database. We designed a webpage for users to search the shop.
As it’s shown above, users need to type in the name of a shop with its zip code for our yelp refiner to locate the specific shop. Then, it will automatically run keyword generation function back-end for a while. The result with ten keywords and phrases will pop out.
Besides, we also want to present results from a commercial nature language processing service, AlchemyAPI as comparison, so the connection to AlchemyAPI has been built.
AlchemyAPI can get keywords in very short time, since it only choose the most frequent keywords. Besides, it only generates keywords, not phrases. Compare with the result of AlchemyAPI, our result is mixed with single words with phrases, which is a adjective with a noun. That is the evaluation of our experiment above usual keyword generation methods, which is to pick out the most unique, not just the most frequent, keywords and phrases.
Comparing our results with the result from AlchemyAPI, it is clearly that AlchemyAPI just selects noun words and phrases instead of adjective ones while our project results can return some non-noun keywords.
We deploy a website to present the keywords. The website is built by Django which can use the keyword-generating function in the back-end. By typing in a part of the store name and its zip code, users can get 10 keywords of the store. Also, if the store cannot be found in data set, the website also provides a list of relevant stores each with link to its keyword page.
The website, however, has to take approximately 30 s\~2 min, according to the programming environment, to present the keywords. It is slightly beyond the tolerance of a visitor, but there are still improvements we can do, such as generating keywords before query and storing them in a database, or conduct the algorithm in parallel. Furthermore, we can still improve the algorithm to 1) generate the sentiment tendency of a keyword or phrase, and 2) eliminate the confusing keywords to improve the user experience.
Distribution of Team Members:
Xiangyu Liu: algorithm and main function, contributing 25% of total work.
Yuqi Qian: website deploy, contributing 25% of total work.
Yongkai Wang: data collection, data cleaning, 25% of total work
Shenshen Wu: data cleaning, presentation, 25% of total work.
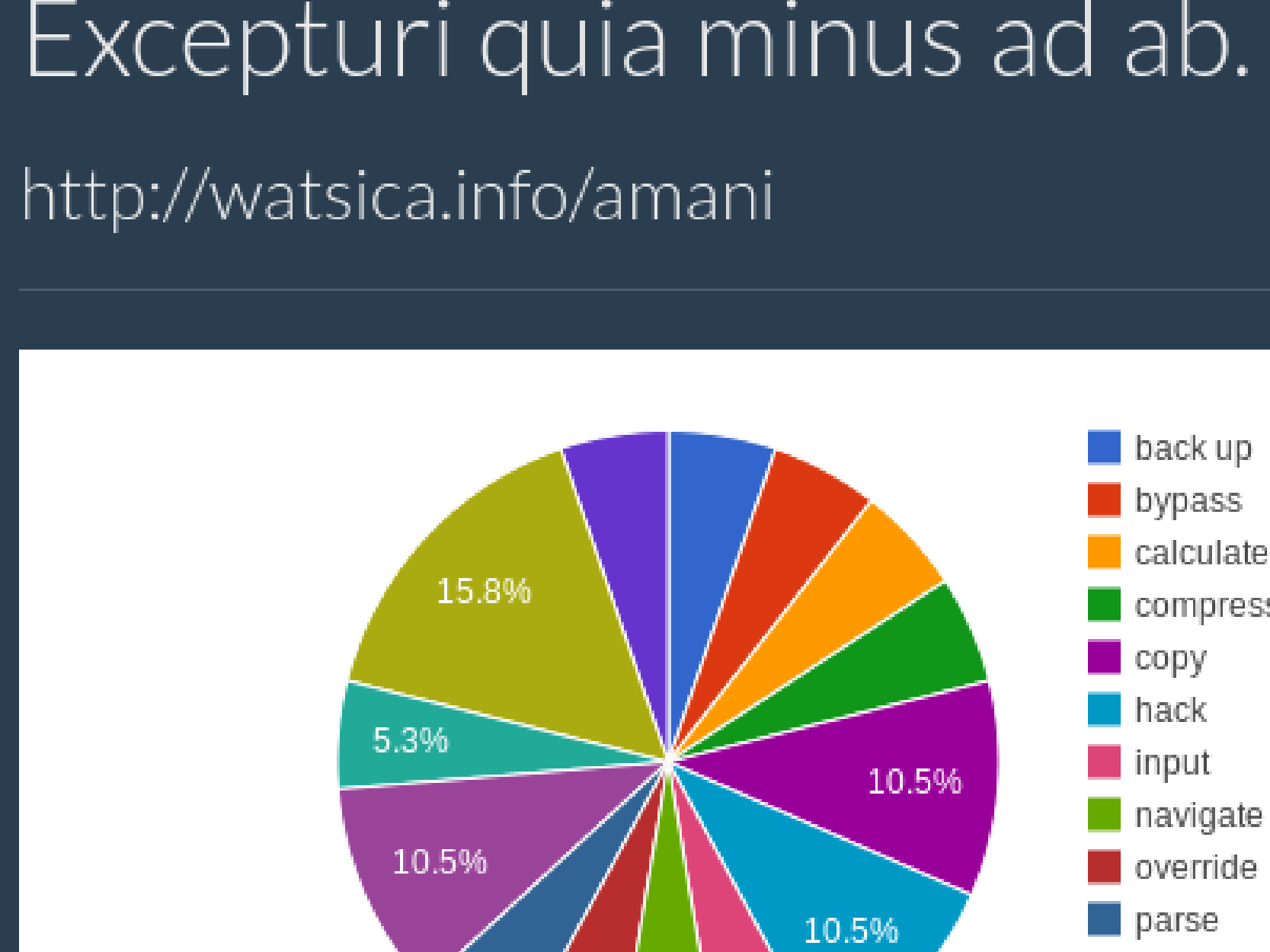
To help website owners to get informed of the traffic of their websites, Blocmetrics provides simple statistics to the call of a website by inserting a client-side JS snippet in target web page and showing statistical chart on Blocmetrics side
Blocmetrics provides free web analysis and reporting by a client-side JS snippet that sends data when the web page including it is called, a server-side API that captures and save this information to database, and a front-end graph showing the statistical chart based-on database.
The client-end JS snippet is a simple function blocmetrics.report() whose source code can be called online or parse directly into the user’s web page. Once the page is called, blocmetrics.report() send customerized information to Blocmetrics. The server-side API is actually a controller having a certain route, the controller receives and saves the data when the route is called properly. Finally, we use Chartkick library to present the data on pie chart, bar chart, or line chart.
Sending data from one web app to another always full of uncertain. One major error is Cross-Origin Request Blocked, caused by sending an unauthorized request from one website to the other, which is blocked by rails defaultly in order to prevent risk. The other is No Route Matches Error on Blocmetrics side. We tried to send a POST request to Blocmetrics and we have corresponding routes on server-side, however, we still got this error.
We added a piece of code to walk around CORS
skip_before_filter :verify_authenticity_token
before_filter :cors_preflight_check
after_filter :cors_set_access_control_headers
def cors_set_access_control_headers
headers['Access-Control-Allow-Origin'] = '*'
headers['Access-Control-Allow-Methods'] = 'POST, GET, PUT, DELETE, OPTIONS'
headers['Access-Control-Allow-Headers'] = 'Origin, Content-Type, Accept, Authorization, Token'
headers['Access-Control-Max-Age'] = "1728000"
end
def cors_preflight_check
if request.method == 'OPTIONS'
headers['Access-Control-Allow-Origin'] = '*'
headers['Access-Control-Allow-Methods'] = 'POST, GET, PUT, DELETE, OPTIONS'
headers['Access-Control-Allow-Headers'] = 'X-Requested-With, X-Prototype-Version, Token'
headers['Access-Control-Max-Age'] = '1728000'
render :text => '', :content_type => 'text/plain'
end
endAfter checking the server log, we found that what client-side send is not a POST request but a OPTION request, so we add this code to route.rb to allow the request.
match 'events.json' => "events#create", via: :options, as: :events_optionsSuch as Read It later, this is a website allow user to save bookmarks for the web pages as archive or to share them with friends. Bookmarks are arranged by topic and open to other users, who can like or dislike the bookmark. Users can always found the bookmarks they created or liked in their portfolio. For the flexibility, topics and bookmarks can be created by sending a simple email.
One of the major feature of Blocmarks is that it can create topics by emails sent by users, which is managed by a heroku addon, Mailgun. The mailgun server receives emails from user and transforms its content into http request, then send it to Blocmarks server. Blocmarks, routers the request to corresponding controller and action, then manage the database.
Other major feature is that Blocmarks generate preview automatically when user saves a url as bookmark. The feature is achieved by Embedly, a service which can grab picture in target website.
We encountered problems when we tried to send http request from mailgun to Blocmarks. We found that mailgun send request to Blocmarks, which does not route to correct action.
To solve the redirect problem, we use Httparty gem to simulate http request, which helps a lot when debug at local. However, Blocmarks do receive the simulating request and treat it properly, on local and online. So The difference between Mailgun’s request and simulating request must be the problem. Finally, we find that Mailgun request has more complicate structure so that Blocmarks cannot get correct parameters. The problem was solved after we implemented the request retrieve method.
As its name indicates, Blocipedia is a imitation of Wikipedia, where users can create their own wikis and share them publicly or privately.
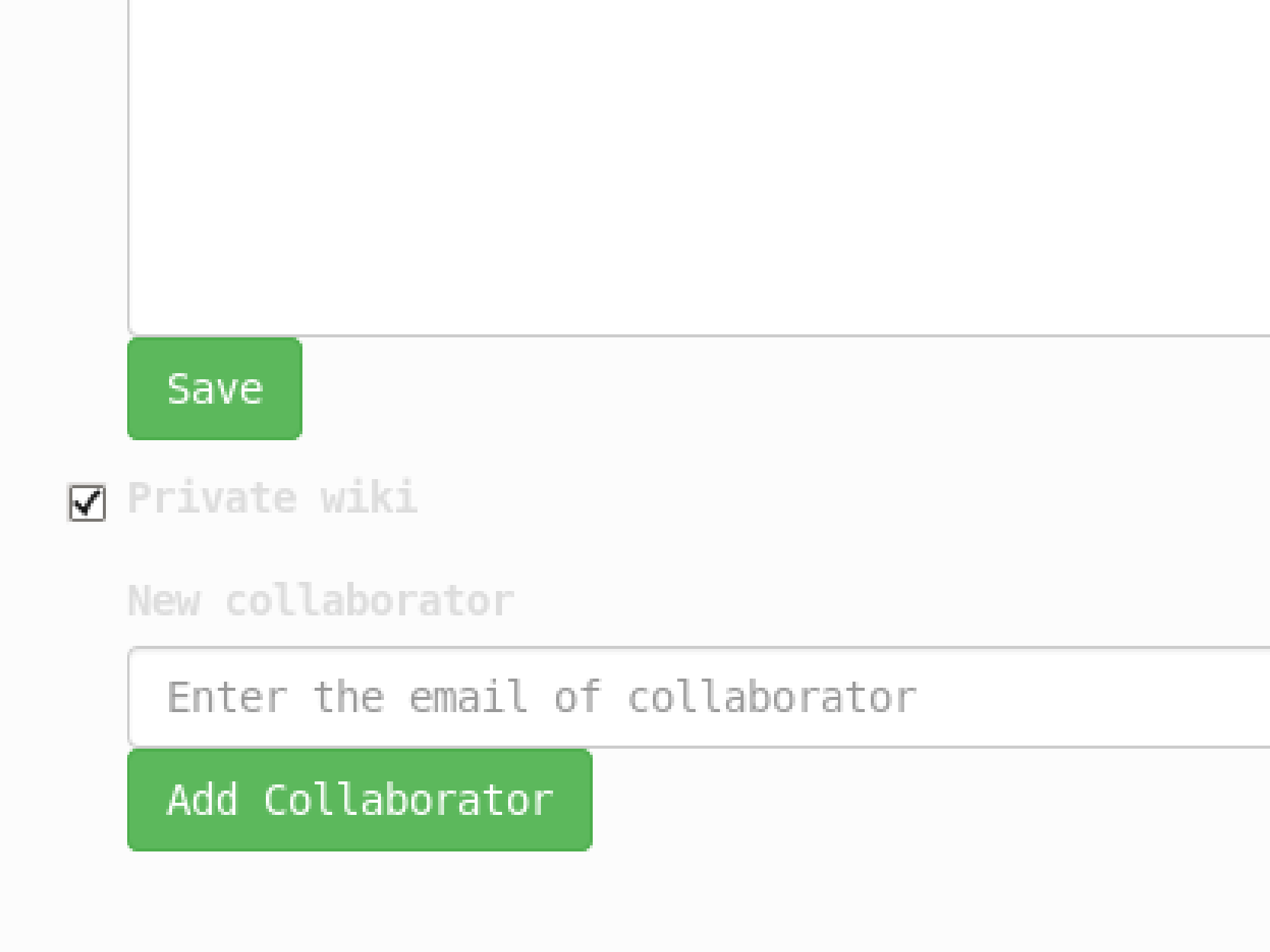
The major difference between Blocipedia and Wikipedia is that we allow private wikis in Blocipedia. Users can upgrade to premium and thus be able to create private wikis which is open to those who is given privilege by the creator.
How to connect the user role with the payment status was one of the major problems. The other is how to add and remove user who is accessible to a private wiki.
The first problem can be solved by using Stripe Gem, and ChargesController, where a create action is used to link successful charge to upgrading user role.
def create
customer = Stripe::Customer.create(email: current_user.email, card: params[:stripeToken])
charge = Stripe::Charge.create( customer: customer.id, amount: 100,
description: "BigMoney Membership - #{current_user.email}",
currency: 'usd'
)
up_grade
redirect_to current_user
rescue Stripe::CardError => e
flash[:error] = e.message
redirect_to new_charge_path
endThe up_grade is defined in a helper
def up_grade
if current_user.role == "standard"
current_user.update_attribute(:role, "premium")
end
if current_user.save
flash[:notice] = "You have successfully upgraded your account!"
else
flash[:error] = "Error"
end
endThe other problem, adding collaborator to a private wiki, is more complicated than it looks like. First, we have to keep a many-to-many relation to record the relation between private wikis and users. Second, we need to search a user by his email on wiki#update view without reloading the page. Third, we have to show wiki collaborators to the owner, along with links to remove each of them.
Since rails and its database(SQLite and PostgreSQL) are not convenient with many-to-many relationship, we use Redis gem to retrieve the list of private wikis that certain user has access to, and the list of users that certain private wiki are open to. We add have_access_to action to user’s model in user.rb and give_access_to, open_to, delete_collaborator action to wiki’s model in order to create, show, and remove collaborators
def have_access_to
wiki_ids = $redis.smembers(self.redis_key(:have_access_to))
Wiki.where(:id => wiki_ids)
end
def give_access_to(user)
$redis.multi do
$redis.sadd(user.redis_key(:have_access_to),self.id)
$redis.sadd(self.redis_key(:open_to), user.id)
end
end
def open_to
user_ids = $redis.smembers(self.redis_key(:open_to))
User.where(:id => user_ids)
end
def delete_collaborator(user)
$redis.multi do
$redis.srem(user.redis_key(:have_access_to), self.id)
$redis.srem(self.redis_key(:open_to), user.id)
end
endTo add the collaborators, we created CollaboratorController and corresponding views, js, and partials. We use jquery so that adding collaborator can be done without reloading the page. To show the collaborators, the partial _collaborator.html.erb is called by wiki#show. The javascript create.js and destroy.js is added so added or removed collaborator will show or hide automatically. More detail can be found in GitHub